




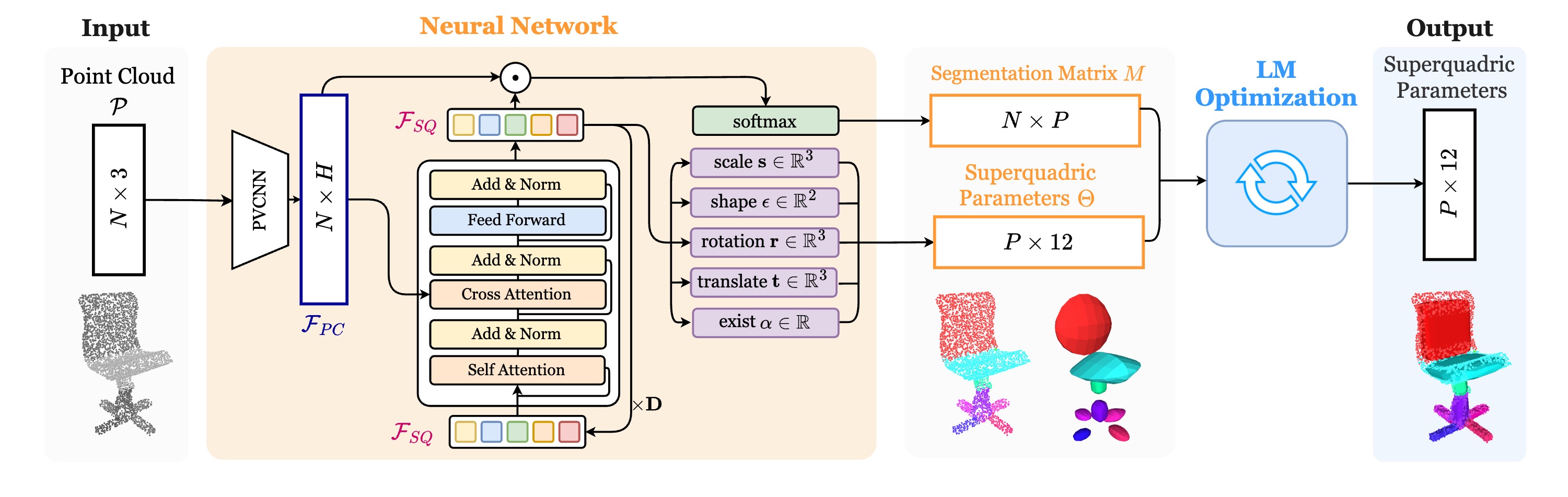
Overview of SuperDec. Given a point cloud of an object with N points, a Transformer-based neural network predicts parameters for P superquadrics, as well as a soft segmentation matrix that assigns points to superquadrics. The predicted parameters include the 11 superquadric parameters and an objectness score. These predictions provide an effective initialization for the subsequent Levenberg–Marquardt (LM) optimization, which refines the superquadrics.
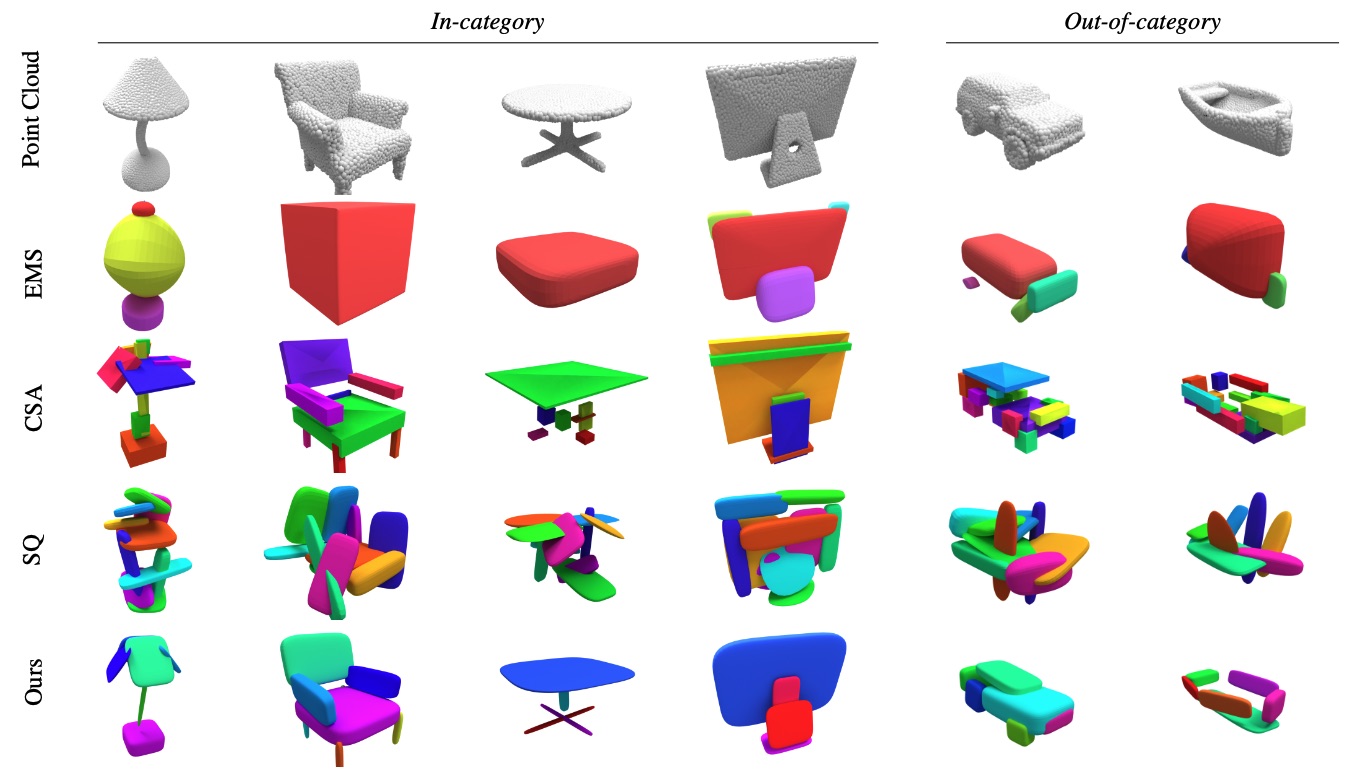
We evaluate the performance of SuperDec to decompose individual objects on ShapeNet, a traditional object dataset.
To evaluate both accuracy and generalization, we conduct two experiments: in-category and out-of-category. In the in-category experiment, all learning-based methods are trained on the full ShapeNet training set (13 classes) and evaluated on the corresponding test set. In the out-of-category experiment, models are trained on half of the categories (airplane, bench, chair, lamp, rifle, table) and evaluated on the remaining ones (car, sofa, loudspeaker, cabinet, display, telephone, watercraft).
We compare with three baselines: EMS [2], SQ [3], CSA [4].
Our model trained only on 13 ShapeNet categories, can be extended to 3D scenes without any additional fine-tuning. Specifically, given a 3D scene point cloud, we obtain object instance mask using Mask3D, center and rescale them, and directly input them into our model. We visualize the results for some scenes from the Replica dataset.
















We envision SuperDec enabling a wide range of applications, especially in robotics and controllable content generation.
We have explored how our representation can be used in robotics by evaluating in real-world for the tasks of path planning and object grasping. Given a scan of a real-world 3D scene captured with an iPad, we use SuperDec to compute its superquadric representation and we compute the grasping poses for some of the objects present in the scene.


We have also explored how our representation can be directly leveraged to introduce joint spatial and semantic control in the generations of text-to-image diffusion models. To do that we generated some images by conditioning a ControlNet on the depths of the superquadrics extracted from some Replica scenes. We have seen that the superquadric representation can be used to achieve both spatial and semantic control of the generations.












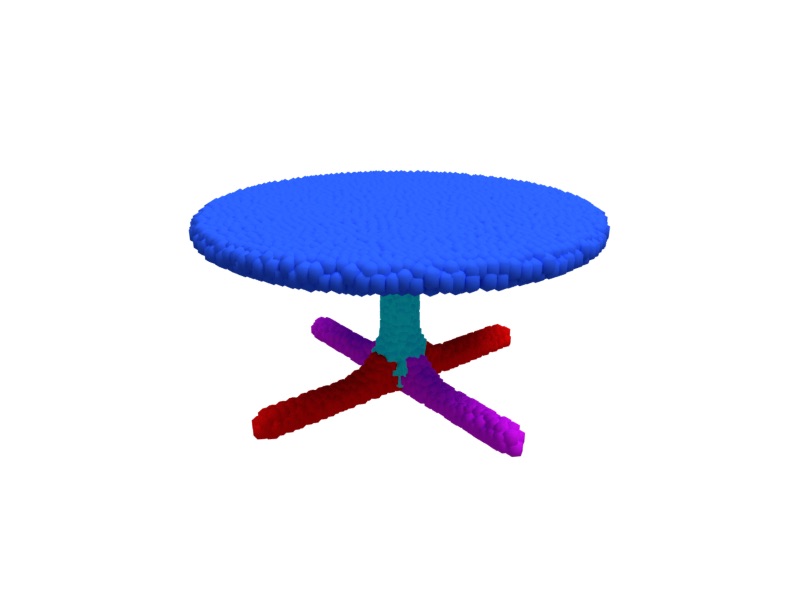
Our method not only learns to predict the parameters of the superquadrics representation, but also the segmentation matrix which decomposes the initial point cloud into parts which can be fitted by the predicted superquadrics. Below, we visualize the predicted segmentations for the same examples from ShapeNet. We observe that segmentation masks, appear very sharp and this suggests that our method, especially if trained at a larger scale, can be leveraged for different applications as geometry-based part segmentation or as pretraining for supervised part segmentation.



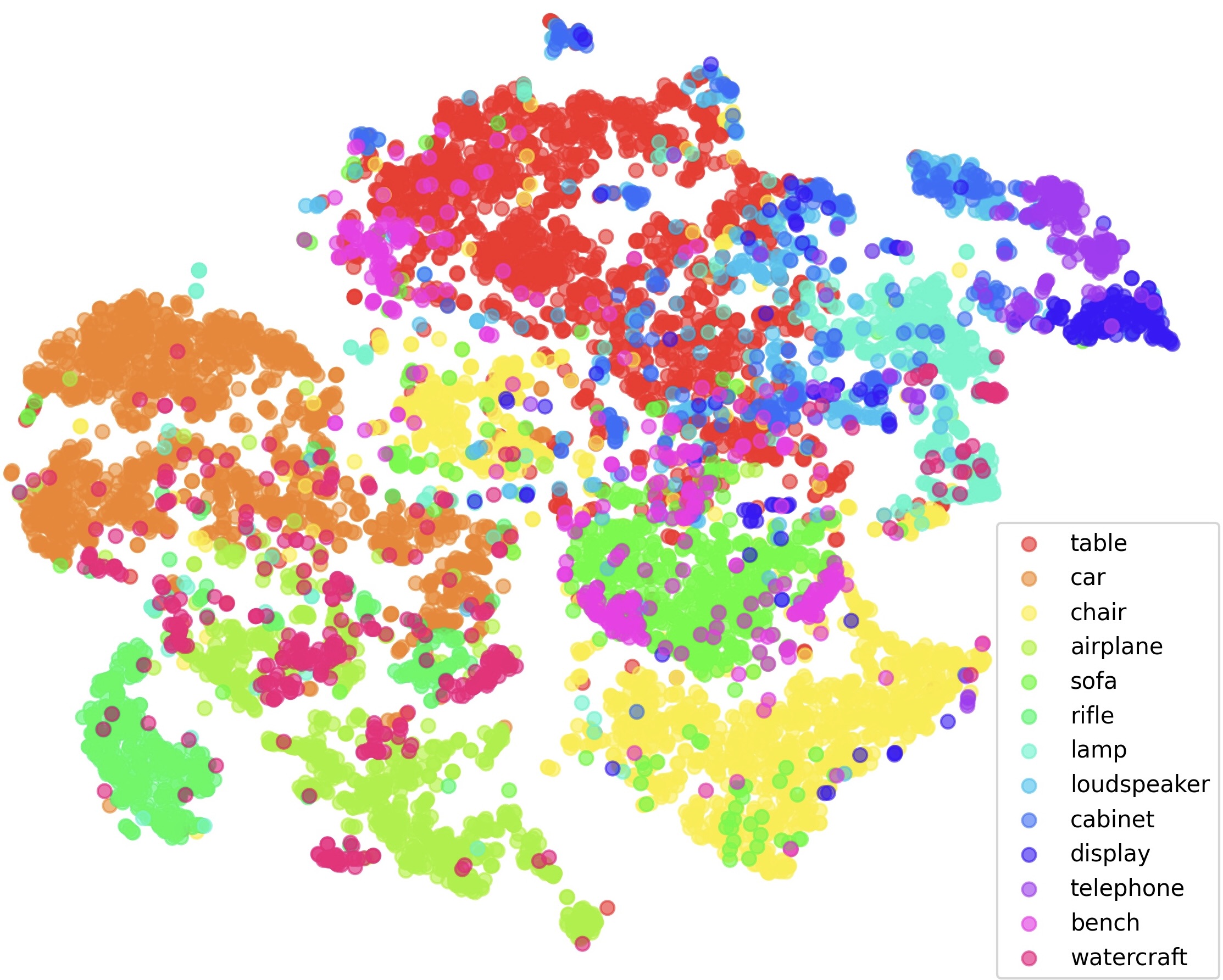
Since our network is completely unsupervised in segmenting objects into parts, in this experiment we analyze the features learned by our Transformer decoder across different object classes. To do that, similarly to BERT's [CLS] token, we append a learnable embedding to the sequence of embedded superquadrics. While this additional embedding is never explicitly decoded, it intuitively learns to extract meaningful features during self- and cross-attention layers. After training the model with this additional embedding, we decode it at test time and save the resulting vectors across different ShapeNet object categories. Below, we show a t-SNE visualization of those. We observe that categories with consistent object shapes, such as chairs, airplanes, and cars, form distinct clusters, whereas classes with greater shape diversity, such as watercraft, spread across a larger region of the plot. This result suggests that our model is able to cluster objects based on their geometrical structure, without the need for any annotation.
@inproceedings{fedele2025superdec,
title = {{SuperDec: 3D Scene Decomposition with Superquadric Primitives}},
author = {Fedele, Elisabetta and Sun, Boyang and Guibas, Leonidas and Pollefeys, Marc
and Engelmann, Francis},
booktitle = {{Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}},
year = {2025}
}